

サイトを運営しているとGoogleウェブマスターツールに
「重複するメタデータ」「短いメタデータ」などの表示がでてきます。
(HTMLの改善を見るとでてきます)
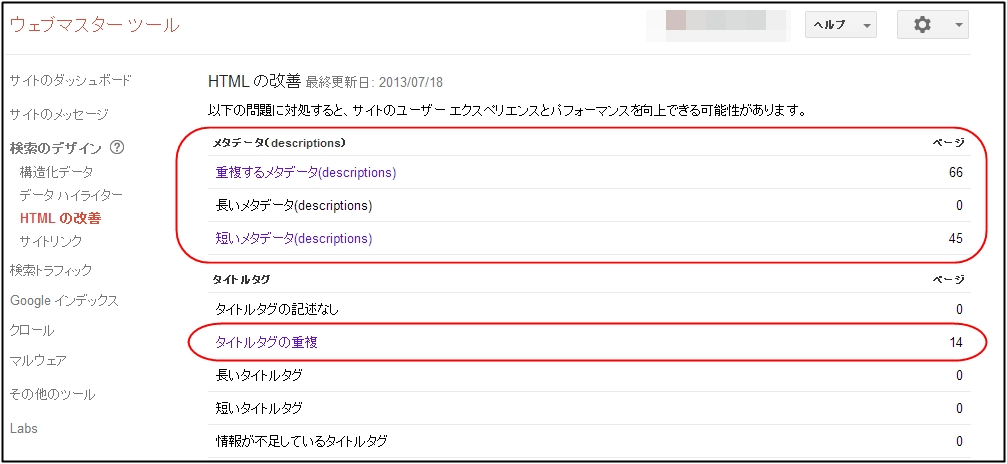
上記のような重複するメタデータや、タイトルタグなどです。
これらをこのまま放置していてあまりに数が多くなると
Googleより低品質サイトの判断をされる可能性があり検索エンジン上よくありません。
重複するコンテンツは、Googleのサイト評価が下がります。
必要ないURLはインデックスさせない設定ができるので、こちらで解説していきます。
Googleウェブマスターツールを確認する
Googleウェブマスターツールに、運営するサイトを登録しておくと、
サイトのHTML重複コンテンツなどが反映されてきます。
下記の画面で確認していきます。
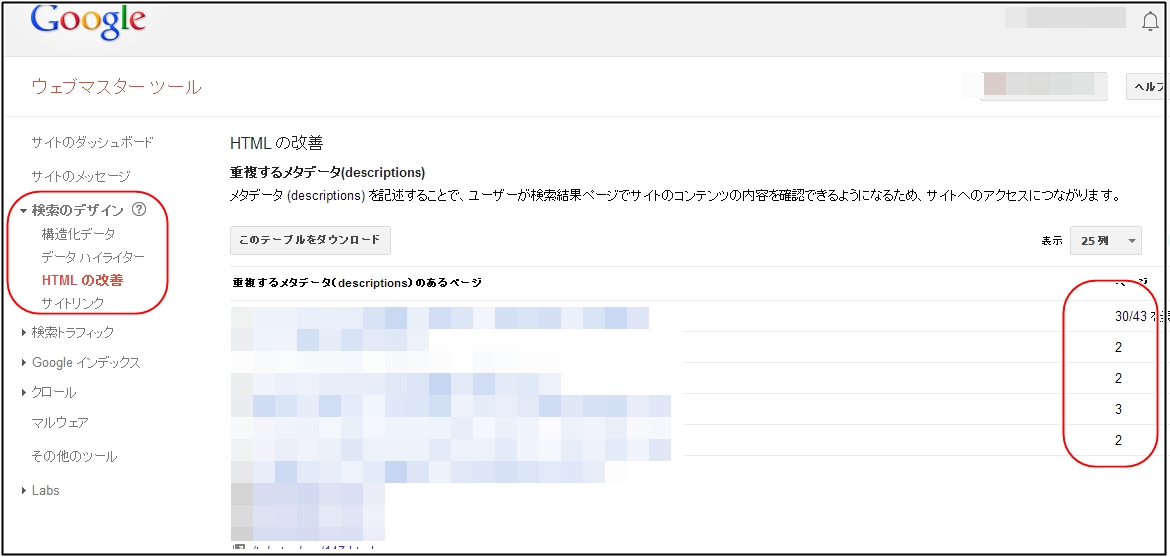
画面の「検索のデザイン」→「HTMLの改善」で重複などが表示されます。
こちらで表示される以下のような表記を確認します。
(例)
/author/kyoheistyleky/page/4
/author/kyoheistyleky/page/5
/author/kyoheistyleky/page/7
/author/kyoheistyleky/page/8
/author/kyoheistyleky/page/9
/category/otokojuku/page/2
/category/otokojuku
/category/like-or-love
上記でわかる重複するコンテンツで、
- 例えば、/author/のコンテンツが重複なのでインデックスさせなくても良い場合
- 例えば、/category/のコンテンツが重複なのでインデックスさせなくても良い場合
(これらをインデックスさせなくても、単独のURLがインデックスされているので良いとする)
robots.txtを利用してnoindex(インデックスさせない指定)設定にすることができます。
サイトURLがインデックスされているかどうかを確認するには
サイトURLがインデックスされているかどうかは
【site:example.com】と検索する事で表示されます。
参照:検索エンジンにURL登録インデックスされていることを確認する方法
各種SEOツールで確認もできます。
Googleウェブマスターツールのエラー内容の確認にも使えます。
robots.txtの使い方
robots.txtとは、
サイト内のインデックスしたくないURLをテキストに記述して
運営サイトのサーバー指定箇所にアップしておくことにより
そのURLがインデックスされなくなります。(noindex設定)
手順は以下になります。
- noindexしたいURLをピックアップする。
- robots.txtファイルを作成する。
- 運営サイトのサーバー指定箇所にアップロードする。
それぞれ解説していきます。
noindexしたいURLをピックアップする。
Googleウェブマスターツールで、
重複コンテンツなどを確認し、noindexにしたいURLを確認します。
robots.txtファイルを作成する。
robots.txtの中身は以下の様に記載します。
User-agent: *
Disallow: /author/
「Disallow:」の後ろに記載しているディレクトリ名が
noindexにしたいディレクトリとなります。
複数のエントリーを記述する事もできます。
記述例
- サイト全体のブロック
Disallow: / - testディレクトリの、index.htmlをブロック
Disallow: /test/index.html - サイト全体のpdfファイルだけをブロック
Disallow: /*.pdf$
[実用的な記述例]
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/cache/
Disallow: /wp-content/languages/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-content/upgrade/
Disallow: /*.php$
Disallow: /*.js$
Disallow: /*.cgi$
Disallow: /*.xhtml$
Disallow: */?tag$
Sitemap: あなたのドメイン/sitemap.xml
Sitemap: あなたのドメイン/sitemap.xml.gz
「Disallow:」の後ろにウェブマスターツールで確認した
noindexにしたいURLディレクトリを追加していきます。
記述が終了したら、当然ながら
テキストファイルで「robots.txt」というファイル名で保存します。
一番簡単な設定方法
WordPressでサイトを作成している場合は、
殆どの場合以下のURLはインデックスする必要がないので、記載しておきます。
[すべての検索クローラを対象として、「/wp-」のディレクトリをクロールしない記述。]
/wordpress/wp-*
/wp-*
注意事項
- Googleウェブマスターツールに表示されている重複メタは、ひとつは残していても問題ないです。
- robots.txtは、日本語表記だと反映されないのでURLを変換して貼り付けます。
運営サイトのサーバー指定箇所にアップロードする。
上記の作業でrobots.txtファイルを作成したらサーバーにアップロードします。
「運営サイトドメインのフォルダ」→「public_html」
こちらの階層にrobots.txtをアップロードします。
WordPressの場合でプラグイン「XML Sitemap」を使用している場合は、
プラグイン「XML Sitemap」の設定より
サイトマップのURLを仮想 robots.txt ファイルに追加
こちらのチェックを外します。
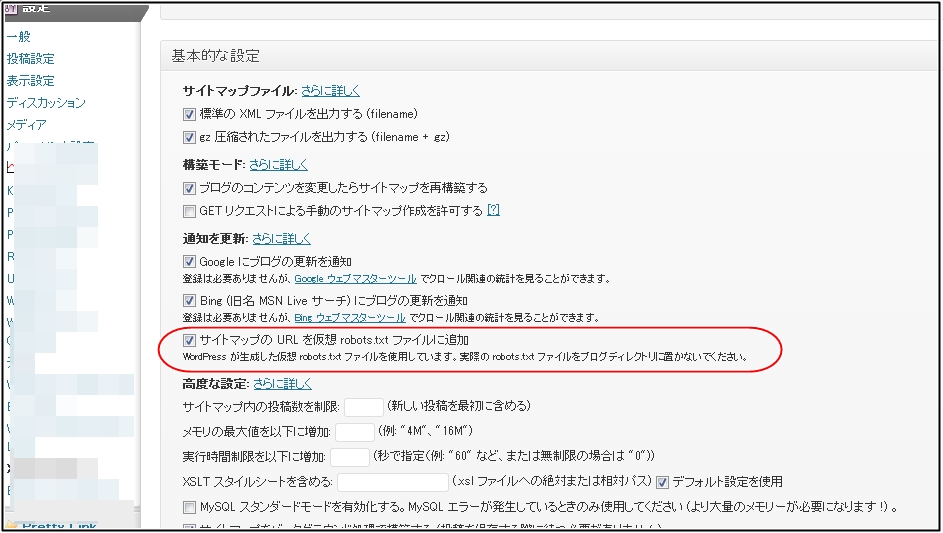
上記赤枠の部分になります。
robots.txtの設定が完了したら
上記の設定が完了しましたら、
Googlebotが次にクロールした時に、インデックスの削除が行われます。
設定の確認方法
設定したサイトURLの末尾に「/robots.txt」と入れてアクセスすると、
robots.txtの設定がブラウザで確認できます。
例:http://www.example.com/robots.txt
(http://www.example.com部分は、設定したサイトURLになります。)
それでもインデックスされ続けている場合
まれにrobots.txtで設定してもインデックスされ続けている場合があります。
これは他のサイトからリンクされていたり、他サイトにURLが記載されている可能性があります。
その場合にどうしてもnoindexにしたときは、
以下の記述をnoindexにしたいディレクト全てのページに記述します。
<meta name="robots" content="noindex">
上記meta nameの使用上注意点
robots.txtのDisallow:と
<meta name="robots" content="noindex">は
同時に使用できません。
robots.txtのDisallow:に指定があると、Googlebotがそのページのクロールをしないので
改めて設置したnoindexの記述をGooglebotが確認できないためです。
metaタグとrobots.txtどちらがよい?
基本的にはmetaタグでインデックス制御する方が、各ページごとに設定できて丁寧です。
robots.txtでブロックするとクローラーがアクセスできなくなるため、
そのURLページの中身を確認できなくなります。
その結果、
metaタグが「index」なのか「noindex」なのかの判断もできなくなることから、
他のページからリンクがある場合などに検索結果にページがあることを表示してしまうことがあります。
(その場合もrobots.txtで指定しているページ内はクロールされません)
robots.txtはそれらの状況を踏まえた上で使用することを推奨します。
WordPressの場合は、各記事URLごとにmetaタグを設定するのも手間なので
robots.txtを重宝すると思います。
まとめ
robots.txtを使って上記の記述をしておけば、
ディレクトリ単位でインデックス制御をする場合に便利です。
ウェブマスターツールの重複が解消されると、
サイトの検索エンジン上評価が高まりますので状況に応じて利用していきましょう。
またカテゴリーページの重複部分ですが、
それ自体が原因となってペナルティを受けたりすることは現状可能性が低いです。
グーグルは閲覧ユーザビリティを重視しているので、
数値上のものよりもカテゴリーページがきちんと存在するユーザビリティが大切です。
重複コンテンツを減らす努力もしつつWEBサイト構築の
基本的な概念も理解して取り入れていきましょう。
関連記事
robots.txtは、Wordpressプラグインを使用して設定することもできます。
参照:WordPressプラグイン KB Robots.txt


コメント